Ceci est le transcript de la conférence que j'ai donné à Paris Web le 2 octobre 2015.

Bons Robots, Mauvais Robots
Un Intense Trafic
Paris Web 2015

Bonjour, je suis venu spécialement de Berlin pour cette dixième édition de Paris Web.
Après 10 ans de Paris Web, enfin ma première conférence !
Cris et applaudissements dans la salle ...
Je travaille actuellement à EyeEm en tant que développeur front-end ... Ou développeur back-end, ça dépend des jours ...
Le phénomène dont je vais vous parler, je peux l'observer tous les jours dans le cadre de mon travail à EyeEm. Mais c'est aussi quelque chose auquel je suis confronté depuis des années sur tous les sites dont je peux m'occuper.

Aujourd'hui, je vais vous parler des robots !
Et comme nous sommes à Paris Web, c'est donc bel et bien plus précisément des robots web dont il va s'agir.
Alors qu'est-ce que j'entends par robots ?
Tout agent qui utilise le protocole HTTP d'une manière plus ou moins automatisée.
Ou dit autrement, tout ce qui n’est pas un navigateur sous le contrôle direct d’un utilisateur.

Des robots, il y en a de toutes sortes, il y en a tout d'abord des bons.

Les premiers qui viennent à l'esprit (et certainement les plus connus) sont les robots d'indexation : Google, Yahoo, Bing, mais aussi Yandex, Baidu ...
En second, on peut penser aux robots d'analyse de liens. A chaque fois que vous postez un lien sur Facebook ou Twitter, un robot, voir une armée de robots, télécharge immédiatement la page pour en extraire des méta-données.
Enfin, pour faire rapide, on pensera aussi aux aggrégateurs RSS, que l'on peut tous considérer comme des robots. Je n'essayerais pas d'être exhaustif, il y en a bien d'autres.

La seconde grande catégorie, ce sera les mauvais robots.

Premièrement, vous les avez sans aucun doute déjà vus à l'oeuvre, il y a les robots de spam. Ils s'en prennent aux commentaires, aux wikis, au forums, partout où ils peuvent poster.
Ensuite, les robots d'attaque de force brute: ceux-ci vont chercher à deviner une combinaison entre un nom d'utilisateur et un mot de passe, en en essayant une infinité.
Assez proches, certains robots vont être à la recherche de failles de sécurité. Ils vont viser les logiciels les plus connus comme blog, wiki et forums. Pour cela, ils vont scanner certaines URLs très précises qui de votre côté finiront souvent en 404 Not Found.
Enfin, un mot sur les robots de fraude à la publicité, on estime que 10% des bannières sur le web sont cliquées par des robots, cela en vue d'augmenter les revenus de publication non scrupuleuses. Pour ne pas se faire prendre, ces robots tentent d'avoir une activité légitime et parcourent le web pour remplir leur historique et leurs cookies.

La dernière catégorie de robots est un peu une non-catégorie.
Ni bons ni mauvais, on ne sait pas vraiment ce qu'ils veulent, voici les robots bizarres !

Ce sont des robots qui ne vont pas décliner leur identité, ou qui vont utiliser par exemple l'identité par défaut d'une librairie HTTP.
Cela va être des indexeurs mal configurés qui vont tourner en boucle sans réelle stratégie.
Ce sont des scripts codés rapidement par un développeur et pas complètement pas testés.
Oubliés en production, plus personne pour les contrôler, il peut suffire d'un détail, une ressource changeant d'adresse, pour qu'ils deviennent complètement fous.
Bizarrement, plus que les mauvais robots, c'est souvent ceux que vous devrez bloquer. Ils peuvent en effet parfois générer un nombre incroyable de requêtes et peser lourdement sur vos performances.

Cette introduction étant faite, vient la grande question, quelle part du trafic cela représente t-il ?
Et bien, cela va dépendre des sites. Selon l'ancienneté et le nombre de liens entrants par exemple. Mais aussi selon le trafic total: sur un site très grand public par exemple, la part des robots peut se retrouver relativement diluée.
Cela dit, je vais vous donner un chiffre que je n'ai pas généré moi-même mais qui provient d'une étude faite par la société Incapsula.

Selon cette étude, pour la plupart des sites, le trafic des robots va représenter 63 à 80% du trafic HTTP.
Cela peut vous sembler énorme et ça l'est !
Si votre site tourne avec 10 serveurs, cela veut dire que 6 de ces serveurs sont là uniquement pour les robots !
60% de votre facture d'hébergement !

Ce trafic, on va donc essayer de le comprendre et de le contrôler.
En ce qui concerne les bons robots, la bonne nouvelle c'est qu'il sont gentils ...

Les bons robots vont ainsi respecter pas mal de bonnes pratiques, qui vont nous permettre de contrôler leur activité.
- Au niveau global, grâce au robots.txt, on va pouvoir restreindre l'accès à certains agents, à certaines ressources. On va aussi pouvoir définir un nombre de requête maximal.
- Grâce aux Sitemaps, on va pouvoir donner un plan du site, et page par page une fréquence de mise à jour.
- Au niveau de la page, grâce à l'en tête HTML
<meta name="robots">, on va pouvoir dire si le robot doit l'indexer et suivre les liens. - Au niveau des liens, grâce à l'attribut
rel="nofollow", on va pouvoir demander au robot de ne pas le suivre le lien.
Enfin, en cas de problème, les bons robots vont toujours fournir une adresse email ou formulaire pour les contacter. Ce qui peut s'avérer utile.

Les mauvais robots, c'est un tout autre univers.
Ils ne vont pas annoncer clairement leurs intentions et vont tenter de camoufler leur activité.
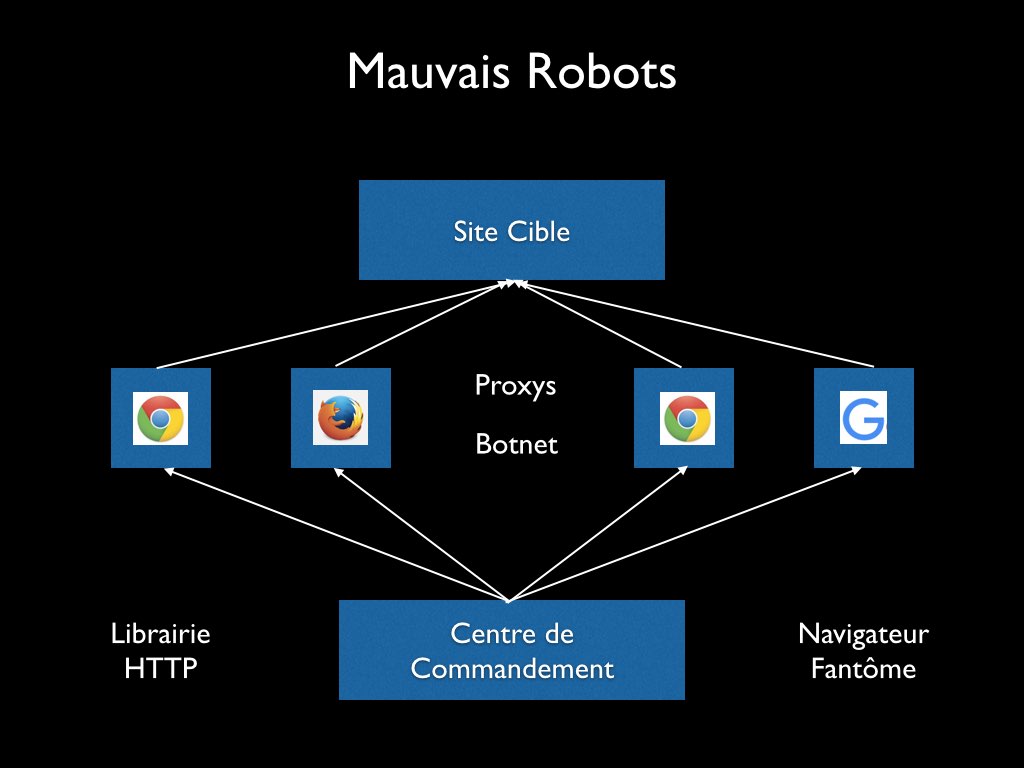
Voici un mode opératoire que j'ai pu voir utilisé par de mauvais robots.
Tout va partir d'un centre de commandement, le cerveau de l'affaire.
Celui-ci va générer à partir de librairies HTTP ou d'un navigateur fantôme ses requêtes malveillantes. Pour se faire discret, il va tenter de changer son identité : Firefox, Chrome, GoogleBot ... Potentiellement, un User-Agent différent à chaque requête !
Enfin, pour encore plus de discrétion, il va s'appuyer sur un réseau d'ordinateurs pour relayer son trafic. Potentiellement, une Adresse IP différente à chaque requête !
Ces ordinateurs sont soit des proxys loués en Ukraine, en Russie, mais aussi en France, soit des ordinateurs personnels infectés par des logiciels malveillants, ce que l'on appelle un botnet.

Bonne nouvelle, les adresses IPs ne mentent jamais, et des APIs existent et permettent de connaître la réputation d'une adresse IP: pour savoir si elle est connue pour avoir récemment eu une activité suspicieuse.
Par exemple:
- XBL : fournie par Spamhaus, société connue pour sa lutte contre le spam email.
- http:BL : fournie par le Honey Pot Project, qui génère sa base de donnée à partir de pièges de types pot de miel disposés un peu partout sur le web.
- TorDNSEL : listant les serveurs du projet Tor, le célèbre réseau d'anonymisation.
Il faut savoir que Tor est certes une fantastique idée pour les dissidents politiques mais que le réseau est aujourd'hui principalement utilisé par les mauvais robots. Au moins, c'est très facile à détecter ...

En plus des adresses IPs, on va aussi pouvoir s'appuyer sur certaines en têtes HTTP pour reconnaître les robots usurpateurs d'identité.
- User-Agent
- Accept
- Accept-Language
- Accept-Encoding
- Accept-Charset
- From
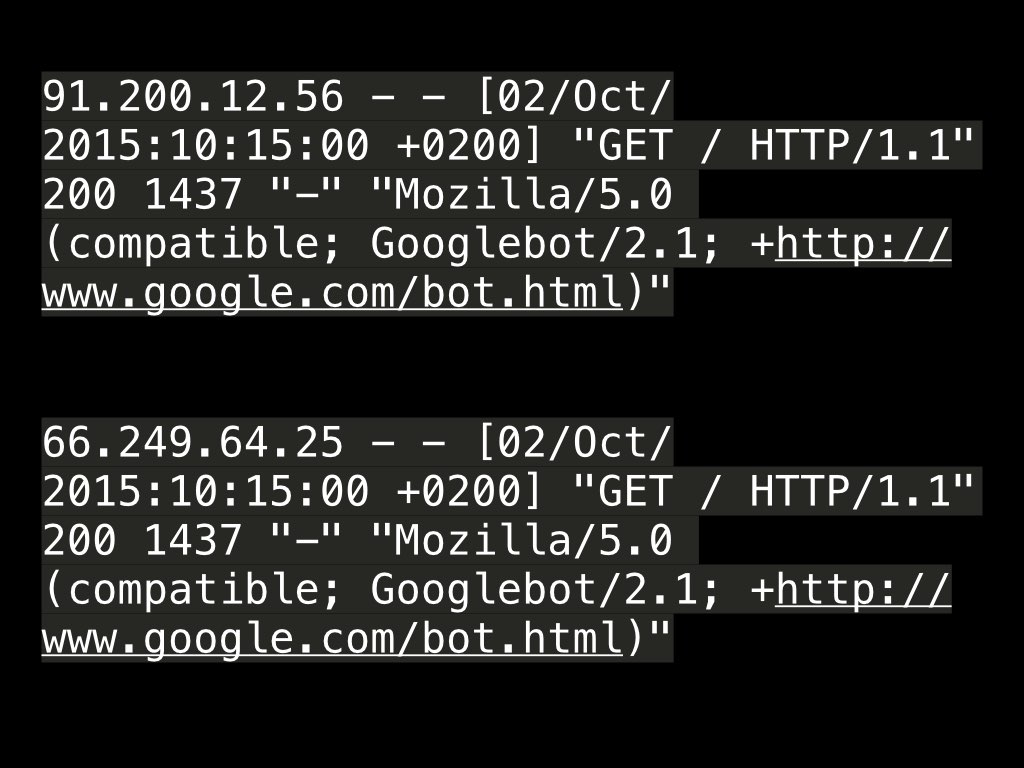
Par exemple, voici deux requêtes tels que reportés dans un Access Log sur le serveur, la trace que laisse une requête HTTP.
66.249.64.25 - - [02/Oct/2015:10:15:00 +0200] "GET / HTTP/1.1" 200 1437 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
91.200.12.56 - - [02/Oct/2015:10:15:00 +0200] "GET / HTTP/1.1" 200 1437 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
Ces deux requêtes semblent bien identiques mais l'une est l'oeuvre du vrai GoogleBot et l'autre d'un robot usurpateur.

On voit que la première adresse IP est bien sur le réseau Google, qu'elle est même sur une liste blanche selon l'API http:BL.
Les en têtes HTTP sont caractéristiques.

La deuxième adresse IP se trouve être un serveur virtuel hébergé chez Linode. Elle est en plus reportée sur des listes noires.
Si on regarde les en têtes HTTP, on note par exemple des différences dans le Accept-Encoding et l'absence de From.
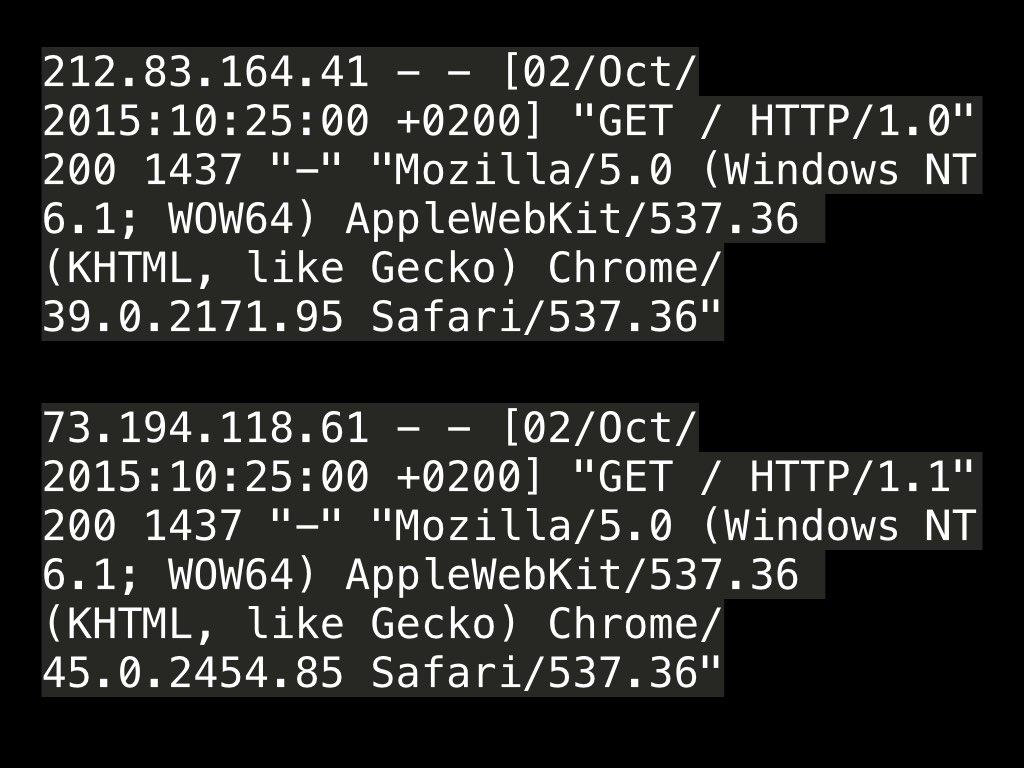
Second exemple rapide, un véritable Chrome et un usurpateur :
212.83.164.41 - - [02/Oct/2015:10:25:00 +0200] "GET / HTTP/1.0" 200 1437 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36"
73.194.118.61 - - [02/Oct/2015:10:25:00 +0200] "GET / HTTP/1.1" 200 1437 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.85 Safari/537.36"

On voit que la première adresse IP vient d'un réseau résidentiel américain (Comcast).
Un navigateur Chrome récent (octobre 2015).
Des en têtes HTTP caractéristiques ...

La deuxième adresse IP se trouve être un serveur Dedibox hébergé en France, reportée sur une liste noire.
Un navigateur Chrome d'il y a un an ... Avec les mises à jour automatiques, c'est étonnant.
Accept header farfelu, comme un vieil Opera ...
Des différences sur tous les autres en-têtes ...
Tout cela pour montrer qu'à l'aide d'un faisceau d'indices, on peut rapidement démasquer les usurpateurs.

Que faire donc face aux robots ?
- Surveiller. On peut se débrouiller en gardant un oeil sur les Access Logs, mais je conseillerais d'utiliser une solution plus avancée. Un tableau de bord basé sur des logs détaillés sera un bon point de départ. On pourra utiliser par exemple la triplette d'outils Elasticsearch/Logstash/Kibana pour cela.
- Protéger. Installer un pare-feu applicatif (Web Application Firewall) est une bonne idée. Si on utilise une application particulièrement vulnérable comme Wordpress, il conviendra d'installer des plugins augmentant la sécurité.
- Ralentir. En général, il faut configurer des limites sur son serveur HTTP, aucun agent ne devrait par exemple être en mesure de faire 100 requêtes par seconde. Au niveau de l'application, il faut mettre en place des limites sur les points chaud: authentification, et toute autre soumission de formulaire.
- Bloquer. D'une manière simple, on ne peut le faire qu'au niveau de l'adresse IP et de l'User-Agent. Cela doit rester l'exception.
Je n'ai donc pas de solution miracle et c'est frustrant. C'est pourquoi, comme je suis un dévelopeur, lorsque j'ai quelques minutes, je travaille sur une solution à ce problème. Malheureusement, je n'ai rien à partager pour le moment, peut-être l'année prochaine à Paris Web 2016 !

Le mot de la fin:
Les robots, c'est un intense trafic qui pèse sur les performances, les coûts, qui fausse les statistiques, qui pose des problèmes de sécurité.
Il ne faut donc pas le négliger.

Les Robots sont parmi nous.
Ne les oubliez pas.
